
Starting In Biotech: Part II
A Deep Dive On Drug Discovery

If you’re just learning about biotech and want a broad industry view, consider starting with this overview of the biotech industry and then diving into drug discovery.
Look up the top 10 companies in biotech, and you’ll get a list of pharmaceutical companies: Eli Lilly, Novo Nordisk, Merck, Pfizer. Biotech is dominated by the development of drugs, in mindshare and in dollars. And while we’ve been trying new medicines for thousands of years, the last few decades have seen an explosion in new approaches and methods. CRISPR, mRNA vaccines, and CAR-T therapy are just a few of the latest approaches to mitigating diseases we’ve suffered from since the dawn of humanity.
To break it down, let’s first step through the different stages of drug discovery. Afterwards, we’ll dive into the different types of drugs and their unique advantages.
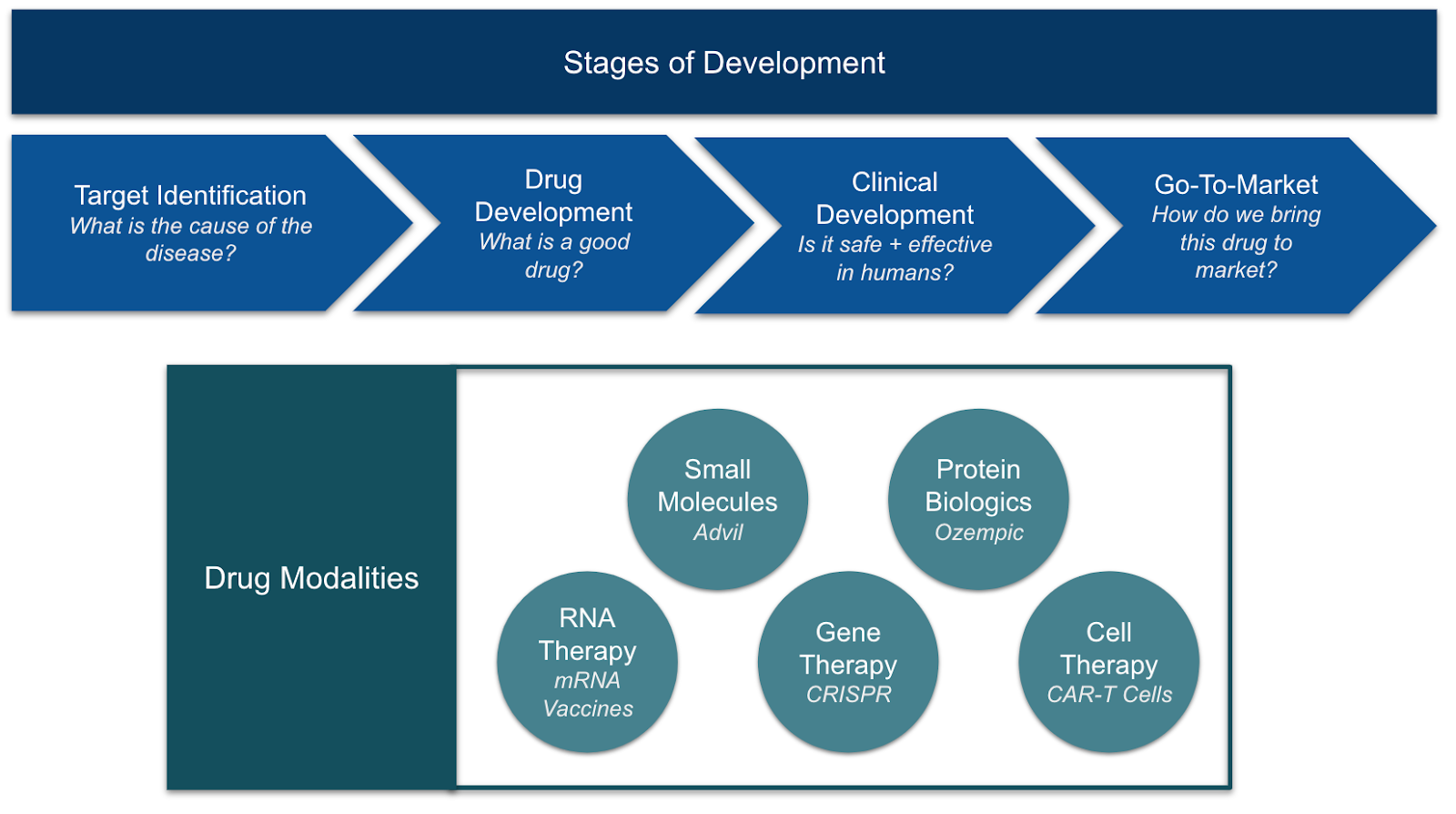
Stage
The drug discovery process is a long journey, spanning from years to decades, that starts with a disease state and ends with a therapeutic. The first step is usually to understand the disease better, allowing scientists to come up with therapeutic ideas and build models to test their hypotheses. These hypotheses are developed and refined over time, ultimately becoming drug candidates that get validated first in animals and then humans, and finally manufactured at scale and distributed to the market.
Target Identification
For most of human history, we had no real understanding of how diseases happen. Hippocrates, father of medicine, felt that an imbalance of the four bodily fluids (black bile, yellow bile, phlegm, and blood) led to disease. Others believed it came from witchcraft, or the alignment of the stars. With no mechanistic knowledge of disease, the only way to find medicine was to try different ingredients and see what worked.
Today our understanding is much improved, and we can often point to a “target” for therapeutics to focus on. Some of the broad categories of disease origin include:
Infectious: An external pathogen like bacteria or virus (influenza)
Genetic: A DNA mutation, at birth or developed over time (sickle cell anemia)
Immune-mediated: The immune system attacks healthy cells or overreacts to external stimuli (rheumatoid arthritis)
Nutritional: Deficiencies in nutrition lead to lack of resources (scurvy)
Environmental: An external toxin causes damage (lead poisoning)
Regulatory: Hormone or metabolic feedback systems break down (type 2 diabetes)
Vascular: Cumulative structural damage leading to loss of function (stroke)
There is no one journey to understand a disease, and two very different approaches highlight that.
A natural drug: In 1964, a medical expedition to Easter Island was collecting samples for potential new drugs (“trying different ingredients to see what worked”). One of the samples found was initially tested as an antifungal, but after the research team saw evidence of immunosuppressive and anti-tumor activity, they started investigating how it worked. It wasn’t until the mid-90s that biologists were able to isolate what protein this compound was affecting. That target, mTOR, turns out to be a core component of the cellular reproduction cycle, and the drug, rapamycin, is now used for a variety of purposes in cancer treatment, organ transplants, and longevity.
Insight in data: In 2003, French researchers were researching families that had extraordinarily high LDL cholesterol. After sequencing their genome, they found a consistent genetic mutation among them, a gene called PCSK9. Two years later, an American team found a cohort with ultra-low LDL, identifying a different mutation in the same gene. This natural experiment surfaced PCSK9 as a prime target for a new drug, and by 2015 two new antibody drugs were approved that dramatically and safely lower LDL cholesterol.
For some diseases, we are now confident about their cause. Sickle cell anemia is almost certainly caused by a mutation in the hemoglobin S gene, and tuberculosis by an infection of the bacteria Mycobacterium tuberculosis. The cause of other diseases, like Alzheimer’s, are still mostly a mystery despite decades of investment. The lack of understanding has made it that much harder to find drugs that work.
The volume and diversity of data being collected is helping to illuminate new possible causes, and a new wave of biotechs are generating and building models based on that data. The hope is that with increasing data and model scale, we’ll start to see emergent behavior that can help us understand how different biological components interact. If these models can more accurately simulate cells or organoids, we can rapidly test changes in input, like DNA, and see how that changes outputs like protein expression, eventually giving us new hypotheses and new therapeutic targets.
Phenotypic Discovery
Some traditional drug discovery approaches skip target identification, focusing on the downstream effects of a drug without requiring an understanding of the mechanism by which it operates (for example, we still don’t really know how Tylenol works). This approach, working solely based on observable changes called “phenotypes,” can remove assumptions about how biology works, potentially unlocking therapeutics for diseases with no known or intractably complex causes. But it provides only minimal information to inform what direction to develop a drug, often leaving us to stumble upon one that works.
Examples: Noetik (Biology Foundation Models), Recursion (Phenotypic AI Models)
Drug Development
With a target in mind, the next stage is identifying a compound or mechanism for affecting that target. Scientists develop proxies to evaluate a compound’s potential effectiveness in humans. Those range from simple chemical tests called assays, to animals genetically modified to exhibit more human-like attributes. At the beginning of the drug development process, faster methods are required to quickly evaluate many different compounds, while late-stage development requires more accurate, but more expensive tests.
Most drug development starts by “screening,” or evaluating a library of compounds. Traditionally, this meant physically running potentially millions of compounds through the assay to see if anything works. Many AI/ML drug discovery companies will now use “virtual screens” instead, where they generate and evaluate ideas computationally before chemically testing only a smaller subset.
If an initial compound is found, scientists continue iterating, trying small changes to see how it improves effectiveness. Other properties start to become more relevant over time, like how effectively it is delivered into a cell, how easy it is to make, or how toxic it might be to other healthy cells. Because of the variety of properties, optimizing one will often lead to degradation in another, making this problem ripe for multi-parameter optimization techniques.
As potential candidate drugs advance through the iterative process, they are tested more thoroughly, both in cell assays (“in vitro”) and in living organisms (“in vivo”). For now, animal studies are still the best and most accurate way to test for the wide variety of effects a drug may have, but a new crop of biotech companies is focused on supplementing or replacing them with AI-predicted properties.
When all is done, a single candidate drug is declared, and an IND (Investigational New Drug) is filed with the FDA to begin human studies.
Examples: Insilico (Generative AI for drug discovery), Axiom Bio (AI drug toxicity models)
Delivery
While therapeutics may work well once inside of a cell, delivering it into the right cells is an entirely different challenge. Our body has numerous defense systems to prevent this from happening, and any delivery mechanism needs to figure out how to evade the immune system, not get metabolized by enzymes in the blood, and pass through the cell barrier intact.
Some drugs can be formulated into pills or liquids and taken orally, while larger and more complex treatments sometimes require more thought. Nanocarriers and other encapsulation systems can safely shepherd drugs through the blood, while a modified virus can deliver DNA directly into a cell and insert it into the genome. Developing the vehicle of delivery is sometimes even more important than developing the drug itself.
Examples: Dyno Therapeutics (capsid delivery), Capsida Biotherapeutics (viral vector development)
Clinical Development
The FDA generally breaks clinical trials into three phases.
Phase 1 is primarily testing for safety and what dosage can be reasonably tolerated.
Phase 2 focuses on effectiveness, measuring actual disease progress in patients, like symptom frequency or tumor size.
Phase 3 is a large-scale study, validating Phases 1 and 2 in a much larger population and monitoring for less common side-effects.
At the end of phase 3, the drug is submitted to the FDA for full approval. The regulatory pathway can also be more complex, with post-approval monitoring (“phase 4”), accelerated approvals for major breakthroughs, and expanded access for patients in need during the trial.
Clinical trials are risky, with over 90% of drugs never making it to FDA approval. They can cost hundreds of millions of dollars to run, making it hard for all but the largest pharma companies to bring a drug to market. Because of this, many smaller biotech companies out-license their drugs early in the process to mitigate the risk of failure.
Executing clinical trials presents a new set of challenges for a drug discovery company.
Protocol design determines in advance which hypotheses will be tested, what the success criteria will be, which patients will be eligible for the trial, and what controls will be analyzed to compare. Patient selection in particular is a critical decision, as many drugs work only on a subset of a population. If a trial is designed poorly, a drug that works very well on a subset of the population might fail the trial anyways.
Immuno-oncology, the use of the immune system to target our own cancers, is one of the most exciting developments in cancer treatment, and can lead to complete remission even in some late-stage patients. It has been transformative for some, but one of the biggest open questions is why it only works on 20-50% of patients. If we could identify which patients these drugs worked on, it would enable better precision therapy and give us a clue on how to design drugs for the remaining patients.
Site Selection and Trial recruitment: The logistics of managing live patients is a large part of what drives clinical trial costs into the hundreds of millions. Companies need to coordinate with hospitals on recruitment and treatment plans, monitor patient progress, and handle patient data all under heavy regulatory scrutiny.
Matching patients with clinical trials is a classic marketplace problem, but combined with extreme time pressure, geographic constraints, and lack of information. New approaches for pairing patients and trials are critical to help drive down the extreme and growing costs of these trials.
Examples: Foundation Medicine (Genomic profiling for clinical trials), Unlearn (AI digital twins)
Go-to-market
Once a drug is approved by the FDA, it can then be sold to patients. This is usually done through clinicians and hospitals, but drugs like Ozempic are a good example of a drug that appears so effective patients are asking for it themselves.
The good news is that by this point, there’s rarely a “product-market fit” issue. If the drug works, people will usually want it and doctors will usually want to prescribe it. The bad news is there are still a lot of challenges remaining. Go-to-market still involves handling pricing, insurance coverage, and reimbursement protocols for drugs. And scaling up manufacturing can require optimizing chemical synthesis, building bioreactors, and creating a supply chain to deliver the drug where it needs to go.
Even at this stage, some drugs can fail to live up to expectations. Exubera, an inhaled insulin drug, failed because of an unwieldy and embarrassing inhaler and a high price. Provenge, a treatment for prostate cancer, took too long to negotiate coverage from Medicare/Medicaid, and had sufficiently severe manufacturing bottlenecks that it was eventually outcompeted by other drugs a few years later. Especially in fast-moving industries where new drugs are on the horizon, biotechs sometimes only have a few years to capitalize on their lead.
Examples: Culture Biosciences (Cloud-connected bioreactors), Komodo (patient journey tracking)
Drug Modalities
While most drug discovery goes through a similar process from target identification to marketing, the approach can differ based on the type of drug. To introduce these types, it’s helpful to briefly review some cell biology.
DNA is the central information repository of the cell. It’s made up of long chains of molecules called nucleotides, and these encode information the same way bits do in computers (but in base 4). Small snippets of the DNA are “read” to make copies called RNA. That RNA is used as a template, where each section of three nucleotides is mapped to produce an amino acid (a codon table shows which patterns map to which amino acids). Chains of amino acids fold into complex shapes as they are synthesized, producing proteins. This is the Central Dogma of biology, that “DNA makes RNA, and RNA makes protein.”
Proteins are the primary actors of the cell, responsible for everything from transporting molecules to defending against pathogens to regulating bodily functions. Those proteins communicate directly with each other, but often use other smaller biomolecules, like hormones and neurotransmitters, to signal information to other proteins. I often think of proteins like functions and small molecules like the variable inputs to those functions, though proteins will often interact directly with each other as well.
With that out of the way, let’s jump into the different ways we can intervene when something breaks.
Small Molecules
You probably consume small molecule “drugs” every day without realizing it. While Advil and Allegra sit in your medicine cabinet, caffeine and ethanol work the same way. These molecules bind into a pocket in proteins, inducing the protein to change shape or enabling the next step in a reaction. The small molecule functions like an ignition key to a protein “lock,” dialing protein function up and down, and new small molecules can be designed to inhibit dangerous proteins or activate dormant ones.
Over the last few decades, structure-based design has become a very popular method for small molecule discovery. It involves looking at the 3D shape of the protein, and using that information to design molecules that might fit into the same pocket. These 3D structures usually come from x-ray crystallography or cryo-EM (cryogenic electron microscopy), but the development of protein folding models like Alphafold have allowed scientists to view hypothesized structures without needing to crystallize a protein.
While this sounds as simple as designing the key for a lock, it becomes much more difficult knowing that:
The key and lock are both flexible, constantly moving and changing shape in the cell.
The key and lock will adapt to each other in surprising ways, changing shape as they get close.
The key can only fit this specific lock, as fitting other locks can cause unwanted side effects.
The key can sometimes fit into the lock, but not “turn,” such that there’s no effect on the protein.
Physics-based simulations like Free Energy Perturbation (FEP) are used to help calculate the likelihood that molecules bind to proteins. More recently, AI-based methods have built on that information to directly predict how well those molecules bind.
Examples: Genesis Therapeutics (AI for small molecule discovery), Rowan Sci (computational chemistry tools)
Protein Biologics
If a protein isn’t working correctly, one option is to add more of that protein directly. Diabetes happens when the body is unable to produce insulin in the right quantities and at the right time in response to glucose levels, and the first mainstream solution to that was directly injecting insulin. As technology has improved, companies can now design more complex proteins to either replicate functionality in the body, or add entirely new mechanisms. Ozempic is one of the most popular examples of this, mimicking the structure of the protein GLP-1 to regulate blood sugar levels, but with improved stability and half-life.
Historically, protein biologics have focused on making small changes to known proteins, helping them last longer or be absorbed better, but protein folding models can again help unlock fully new proteins. If a specific shape is desired, reverse folding models can generate sequences that should fold to produce the desired structure. Understanding the function of a protein from its structure remains a large challenge, and many designs still lean on known structures for inspiration.
Examples: Generate:Biomedicines, Arzeda (AI for protein design)
Antibodies
Antibodies are a special class of protein biologics. The immune system naturally produces antibodies as a defense against malfunctioning cells and foreign invaders, but we can’t always produce the right antibodies to protect ourselves.
Some of the most popular drugs currently on the market are designed antibodies. Keytruda is an antibody cancer drug, part of an exciting wave of therapies in immuno-oncology where the immune system is harnessed to attack cancer. Keytruda targets and inhibits a protein responsible for applying brakes to our own immune system, allowing the immune system to go after those cells. Humira is an antibody used for rheumatoid arthritis, targeting a protein that stimulates inflammation. Both are examples of monoclonal antibodies, which target a single cell marker. Current research aims to develop antibodies targeting multiple markers simultaneously (“bispecific”), and combining antibodies with small molecules to increase effectiveness ("antibody-drug conjugates”).
Antibody generation has historically worked differently than small molecules and other biologics, because we already have a natural system for rapidly designing and testing new antibodies - the immune system itself. To leverage that, scientists can inject the antigen into an animal and then extract the antibodies generated. Those antibodies then need to be “humanized” so they will work in a different species. This approach is called hybridoma technology.
Instead of using live animals, researchers also use “phage display” to simulate an immune system’s generation. It involves producing a large library of protein sequences and fusing them into a special organism called a bacteriophage, which produces the protein on its surface. Phages are tested for how well they bind to the antigen, and the most effective phages have their DNA sequenced to identify the expressing protein. That DNA can then be attached to an existing antibody, which will then hopefully also bind to the same antigen.
While designing antibodies often already works well, optimizing for a wide variety of other properties remains a challenge. New antibodies can accidentally bind to other proteins, trigger unwanted immune system responses, or are difficult to manufacture and keep stable at scale. New computational methods aim both to design antibodies and simultaneously optimize for these new properties to accelerate the development process.
Examples: Absci, Chai Discovery (AI for antibodies)
Vaccines
Vaccines are also a special case of protein biologics. Instead of producing a protein intended to serve some function inside the cell, it is there only to trigger the immune system to produce antibodies for it. The protein itself is an inactive replica or portion of the pathogen the vaccine is meant to prevent. This approach works well when the pathogen is relatively stable, but is less effective for diseases that rapidly evolve or come in a variety of types. For example, the common cold is the result of hundreds of different viruses, while the flu mutates quickly enough that new vaccines are designed every year for them.
Examples: Evaxion (AI for Immunology)
RNA Therapy
In late 2020, the world quickly became experts on RNA therapies, due to the exciting and timely development of the mRNA vaccine for COVID. When mRNA is directly added, cells take it up and start producing proteins from the coded information. In a vaccine’s case, that protein is a component (like the famous “spike protein”) of the virus or undesirable cell, causing the body to ramp up its immune system to clear the protein out and leaving residual protection when the virus later shows up.
Another form of RNA therapies are called siRNAs, or small interfering RNA. They are small strands of double-stranded RNA that, instead of turning into proteins, degrade existing mRNA. They can be used to suppress production of specific harmful proteins. Antisense oligonucleotides (ASOs) work similarly, but in the form of a single-stranded RNA.
The design of an RNA sequence is often relatively straightforward, but challenges remain trying to deliver it effectively. If injected directly, RNA is rapidly degraded by the body’s own enzymes. Wrapping RNA in a delivery vehicle can help it survive longer, but risks more unwanted immune responses or accumulation of RNA into the wrong organs or cell types.
RNA is hypothesized as the very first biomolecule, the true origin of life. The list of RNA types is long and growing, with a new one being discovered as recently as 2021 (GlycoRNA). While early, it seems likely these discoveries will eventually lead to vast new types of therapeutics.
Examples: Atomic AI (AI for RNA therapies), Deep Genomics (AI for RNA therapies)
Gene Therapy
Since the discovery of DNA as the information source of the cell, scientists have dreamed of editing it directly, and modern methods like CRISPR now allow us to add, remove, and replace nucleotides in targeted fashion. For diseases that originate with a genetic mutation, there is no better solution than to fix it at the source.
Gene therapy is most effective when specific genes are broken or missing. In sickle cell anemia, adding new copies of a hemoglobin gene seems sufficient to restore patients to health. Even if the mutation continues to exist in some cells, having other cells with the repaired DNA can often mitigate the disease. In cases like cancer, where even a single cell can cause problems when it replicates, gene therapy has been less effective.
Examples: Profluent (AI designing new gene editors), Mammoth Biosciences (CRISPR gene editing)
Cell Therapy
Instead of adding proteins or DNA, it can sometimes be advantageous to add entire cells. The first bone marrow transplant was done in 1956, and while stem cell treatments didn’t turn out to be the miracle drug we expected in the 2000s, new developments continue to push the envelope of what’s possible. CAR T-cell therapy for cancer is a new approach, where immune cells are extracted from the patient, modified to track down specific tumor cells, and then injected back into the body.
Examples: Sana Biotechnology (engineered cells), Elevate Bio (cell therapy development)
New Approaches
Scientists are always coming up with new and creative ways of developing therapies. Some of those experimental and less validated ideas include:
Microbiome therapeutics: Leveraging healthy bacteria to improve the microbiome.
Oncolytic Viruses: Engineering viruses specifically to seek out cancer cells.
Radiopharmaceuticals: Drugs that target particular cells and emit radiation to kill them, reveal them during imaging, or further target them with other methods.
Molecular glues: Drugs designed to bring multiple proteins together instead of disrupting a single protein.
What Next?
While there is so much we still don’t understand about biology, there are many opportunities for software and AI to work at the cutting edge of research. You hopefully now have a framework to help inform what you’re excited about, and which questions to ask next.
If you’re interested in following along as we investigate some of these biological and technical questions in more depth, subscribe and stay up-to-date with new blog posts. And as always, if you're exploring this space too, I'd love to hear what you're building or learning. Reach out anytime.
Thank you to Alex Goldberg, Anton Krutiansky, Ken Leidal, Lina Garcia, Matteus Pan, Ryan Kagin, and Wojtek Swiderski for taking the time to review this post.