
Starting In Biotech
An overview of the biotech industry for the curious engineer

The biotech developments of the last decade sometimes sound like science fiction. We can directly edit genes to correct inherited diseases, predict protein structures from DNA sequences alone, and develop a working vaccine for a global pandemic in just a few weeks. But for someone who wants to learn more, it's hard to know where to start asking questions.
This is the overview I wish I had when deciding how to join biotech. My aim is to give you a practical framework to understand the breadth of research, a starting point to follow your own curiosity, and some insight into where software and AI can help bring us into the future that biotech promises.
Why work in Biotech?
Biotech is science applied to improve health and save lives. Its impact is deeply human, giving us a few more years with a loved one and the freedom to age gracefully. Its nature is deeply intellectual, interrogating the most complex system the universe has ever created. And its pace is accelerating, with new discoveries coming every year.
There has never been a better time to join the field. While breakthroughs will continue to come from laboratory experiments and clinical insights, software plays an increasingly important role enabling those discoveries and bringing them to market. And with the explosion of biomedical data, AI has the opportunity to uncover connections that were never possible before.
It no longer requires a biology or chemistry PhD to contribute. But it does help to understand a little more of the science, so let’s jump in.
How does biotech improve health and save lives? We’ll start by looking at how biotech directly helps patients. It does so by answering two questions about our health: what is the problem (diagnostics), and how do we solve it (therapeutics). With that context, we will then view the development journey of a product, and how biotech enables researchers, scientists, and clinicians to create and deliver those products to patients.
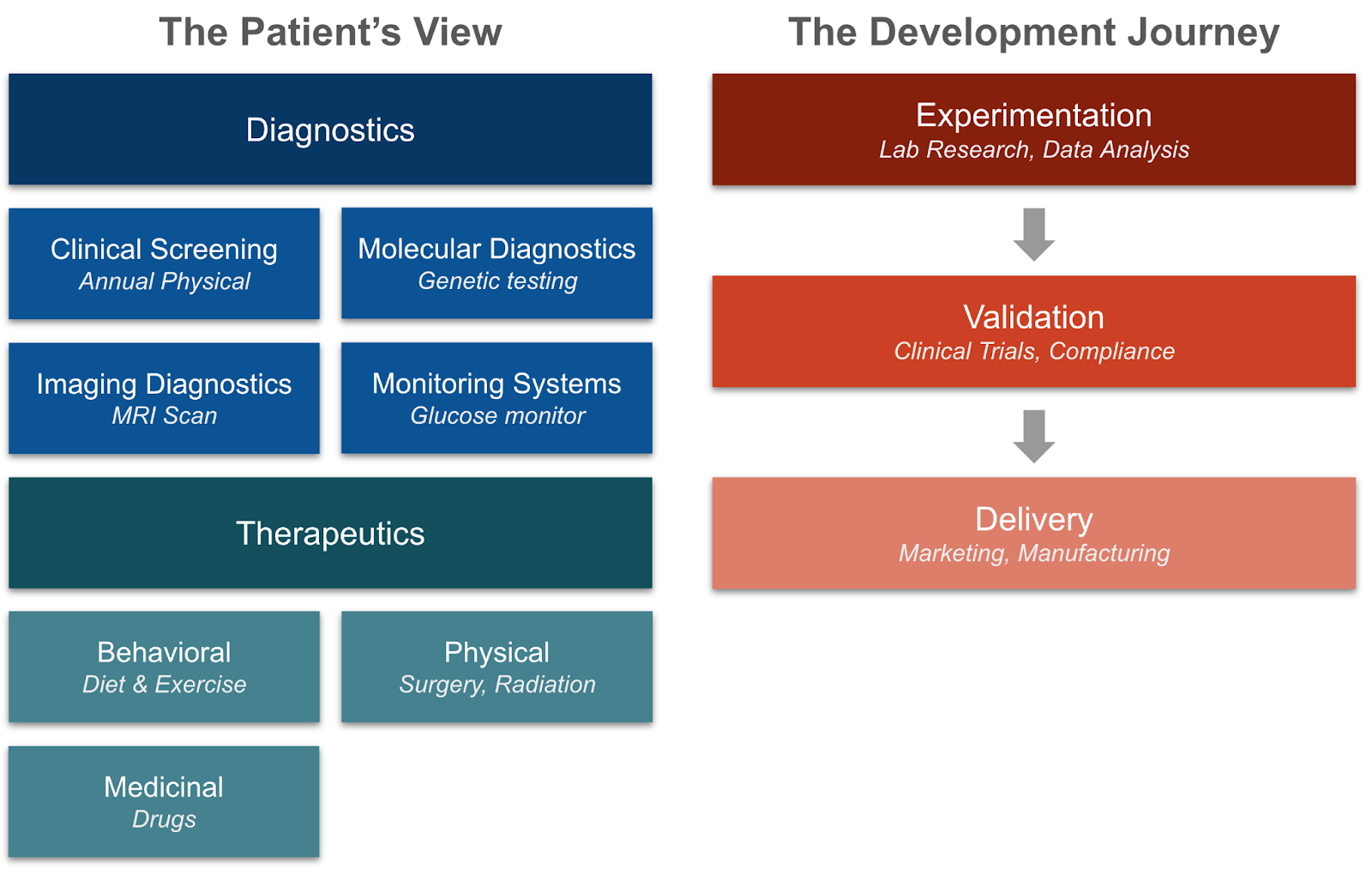
The Patient’s View
Identifying the Problem: Diagnostics
Every health issue needs a diagnosis before a treatment can be applied. Diagnostics help a clinician choose the right treatment, stop an infectious disease from spreading, and prevent a catastrophic failure like a heart attack or stroke. One way to categorize the different approaches is to look at the source and frequency of information.
Clinical screening uses what can be seen, heard, or felt to identify problems. Every time a doctor asks you to cough, every time your gym teacher asks you to run a mile, and every time you have to read EDFCZP at the bottom of an eye chart, you are getting clinical diagnostics. These tests are the first indication of whether something is wrong and whether to follow up with other tests. More recently, these tests are being brought into the comfort of our own homes using nothing but an iPhone or handheld device.
Example biotech companies: TytoCare (home care), BrainCheck (neurocognitive testing)
Molecular diagnostics uses the presence of specific molecules in bodily fluids to diagnose potential issues. Blood panels can tell if your Vitamin D is low or your cholesterol is high. Stool samples can analyze your microbiome for gut health, while an all-too-familiar nasal swab test can quickly detect COVID-19. New tests can even use DNA markers in the blood to identify early signs of cancer.
Examples: GRAIL (cancer detection), Viome (microbiome tests), Sherlock Biosciences (abnormal DNA/RNA detection)
Genetic testing is a special case of molecular diagnostics, extracting DNA to analyze further. While 23andme could tell us what percent of our DNA is shared with Neanderthals, our genome sequence can also determine the presence of a genetic-linked disease or propensity for it. For example, more than 50% of women with a BRCA1 mutation will get breast cancer by age 80, leading many to get preventative mastectomies to avoid it.
The more genomic information we can collect, the more patterns we can find that affiliate genetic mutations with observable changes. Researchers are analyzing enormous datasets containing genome data, lifestyle information, physical measurements, medical imaging, and death registries. This complex multimodal data is ripe for AI models to extract information, and the hope is they can connect genetic changes to health issues, pointing the way towards future solutions.
Examples: Nebula Genomics (whole genome sequencing), Genomenon (gene analysis)
Imaging diagnostics visually examine what’s going on inside the body. The alphabet soup of MRIs, PET scans, CT scans, X-rays, and other imaging tools each have their own advantages. X-rays see dense structures like bones the best, and are great for diagnosing bone fractures. MRIs can provide a 3D view of soft tissues in the entire body, but are much more expensive. And expectant mothers are familiar with ultrasounds, allowing them to hear the most precious sound in the world in real-time, their baby’s heartbeat. New methods are also continually emerging, like photoacoustic imaging, that improve on accuracy or safety.
The most accurate images can only be taken by removing some tissue or fluid first. With samples removed, doctors can see what’s happening at the cellular level under a microscope, like a throat swab to check for strep throat, or a tumor biopsy to identify the type of cancer. The growing field of digital pathology takes images of these scans and analyzes them for more complex and generalizable patterns.
Examples: PathAI (digital pathology), Prenuvo (MRIs for cancer detection), Rad AI (AI for radiology)
Monitoring systems take measurements and give live feedback to the wearer about what’s going on. Digital watches and rings may be fashion statements, but can also track heart rates, blood oxygen levels, and sleep quality. Continuous Glucose Monitors (CGMs) were built to help diabetics manage their insulin, but have also become popular among consumers to help understand how they respond to different foods. And headbands using EEGs are recording brain waves to analyze sleep patterns and help diagnose neurological disorders.
Examples: Dexcom (CGMs), Oura (wearable rings), Beacon Biosignals (brain monitoring)
Where Diagnostics Can Go From Here
Diagnostics is evolving in three different directions, each presenting new opportunities for researchers.
Adding new types of data: How else can we measure what’s happening? Joy Milne demonstrated the astonishing ability to smell Parkinson’s, and researchers are now trying to translate that into a standardized test. Others are working to identify new sources of data inside the cell, extracting ever more granular information on every molecule it contains.
Collecting more data: How do we improve the accuracy, throughput, and frequency of data? CGMs transformed diabetes management by checking glucose levels continually rather than in manual tests, and others are working on monitoring for other key biomarkers. DNA sequencing costs have fallen 100,000x over 25 years, enabling whole genome dataset collection at an unprecedented scale. How else can we scale up existing methods?
Interpreting that data: Across every diagnostic type, data requires analysis to be useful. Data is siloed in individual companies and in disparate formats. Datasets can easily reach into the petabytes, requiring bespoke data pipelines to manage. And all of that data needs interpretation to look for patterns and insights. AI models are already used to review medical images, identify potentially causal genetic mutations, and detect disease markers. As the volume and diversity of data increases, analysis will become ever more challenging and important.
All of these methods can help identify a health issue. What happens next?
Solving the Problem: Therapeutics
A diagnosis alone isn’t usually helpful without a treatment to accompany it. One way to categorize therapeutics is by the type of intervention: behavioral, physical, and medicinal.
Lifestyle and behavior are changes we can enact on our own, though we are often resistant to doing so. The perennial advice from doctors and parents is to eat well, sleep well, exercise, and manage mental health, and those pillars of health still hold true. But as anyone who has tried to squeeze in a morning run before work can attest, it is easier said than done. Companies are building platforms to help make these behavioral changes easier, but it’s likely it will always require some hard work on our part.
Many behavioral changes are preventative in nature. This can make them extremely effective, as it is easier to prevent rather than cure a disease. But it can also make them much harder to apply when there isn’t a burning need to do so immediately (e.g. vitamins vs. painkillers).
Despite its importance, nutrition and exercise science are still not as well understood as many hope, and clean data collection remains a key barrier to understanding. One challenge is the financial incentive, as it is hard to make money recommending something that is freely accessible to all. As a result, clinical trials for diet and exercise have largely been funded by government and non-profits.
Examples: MyFitnessPal (smart food tracking), Tonal (exercise machines), Elemind (inducing sleep), Headspace (meditation)
Physical Interventions directly interact with the body. Surgeries can remove objects, repair damage, or add something new. Whether the surgery gives us a little more confidence or a little more mobility, the technology behind it is quickly advancing. Robots now assist in more than 20% of all surgeries in the U.S., and testing has started for fully autonomous robotic surgeries. Brain-computer interfaces are adding new ways for our minds to communicate with the outside world. And we are finding new ways to augment the human body directly, like vagus nerve stimulation devices and advanced prosthetics.
Non-invasive energy-based interventions are also advancing. Radiation therapy is a common treatment to kill targeted cancer cells, focused ultrasound can stimulate or destroy tissue to treat diseases like Parkinson’s, and phototherapy uses ultraviolet light to treat skin conditions and reduce inflammation.
Examples: Neuralink (brain-computer interfaces), eGenesis (human-compatible organs for transplant), RefleXion (biology-guided radiotherapy)
Medicinal Drugs are usually the first idea that comes to mind when someone thinks of biotech. Humans have been using plants as medicine for as long as there are written records, both medically and recreationally (Cannabis was one of the first medicines in recorded history). Today, drugs take a variety of forms, from small molecules to larger proteins to gene therapies. Some of the most exciting developments in biotech involve using AI to discover new drugs, which I’ll cover in more depth in the next blog post.
Examples: Genesis Therapeutics (AI for drug discovery), Schrödinger (physics-based discovery tools)
Development Of A New Biotech Product
If diagnostics and therapeutics are the products being delivered, how are they made? The development lifecycle follows a path from experimentation, to validation, to delivery.
Experimentation
The seeds of an idea are planted in an errant image, a surprising spike on a chart, or a miraculous mouse. It forms into a hypothesis, and that hypothesis forms into a set of experiments. Every researcher’s workflow looks different, but each has the same goal of illuminating some new truth of biology. This unique path is part of what makes experimentation hard to automate, as there is not a standard set of tasks or steps. That initial “Eureka” moment so often relies on the observant scientist thinking outside of the box.
But despite the bespoke nature of research, there are some common tools to make it faster and more effective. Manual pipetting and stirring has made way for automated robots running experiments programmatically. Beside them, researchers leverage LIMS (laboratory information management systems) and ELNs (electronic lab notebooks) to keep track of results and share them with colleagues. And new foundational biology models aim to enable in-silico experimentation that will inform what experiments or parameters to try next.
A core part of experimentation is the data layer. Collected through every blood panel or clinical image, the amount of data generated in biotech is enormous and quickly growing. By some estimates, a single person’s whole genome scan can reach into the gigabytes even when storing only changes from a reference - multiply that by millions of people, dozens of different types of information, and add in images, and you can see the problem. “Omics”, the shorthand for the collective analysis of any biomolecule (genomics for genes, proteomics for proteins, etc.) has exploded, with new types and scales of data arising all the time, and it is often no longer feasible to analyze on a local computer.
Beyond sheer size, biotech data also suffers from other challenges. The data is often siloed between organizations, batch effects show up with different devices, and it can be hard to infer causality from correlational studies.
All of this data feeds into experiments in an iterative feedback loop. More data raises more questions, requiring more lab work or new data sources to answer. The goal of some biology ML models is to build “closed-loop lab automation,” where the AI is identifying experiments to run, collecting the data, and using that data to inform new experiments without any intervention.
Whether automated or manual, the result of all this experimentation is the prototype of a product - a drug, a test, or a new approach.
Examples: Benchling (cloud R&D platform), Emerald Cloud Lab (Lab automation)
Validation
To ensure every new product is safe and effective, it must go through validation in humans, a process tightly controlled by the FDA.
For diagnostics, validation can mean experimentation across manufacturing sites, tissue types, or patients. Methods are also evaluated for their sensitivity and specificity, making sure they do more help than harm. In therapeutics, it most often means clinical trials. Running these trials is complex, having to manage the trial design, recruitment of potential patients, testing of the new product, and coordination between partners.
Throughout the process, there are strict regulations and compliance requirements designed to make sure quality controls are put in place at each step of the pipeline, patient information is safely handled, and clinical decisions are made ethically.
Examples: Science 37 (clinical trial operations), Flatiron Health (patient and site selection)
Delivery
As with all new products, developing a new diagnostic or therapy is necessary but not sufficient, and the challenge of bringing it to market is complicated by a host of biotech-specific constraints.
FDA approval is often thought of as a binary decision, but it is just the start of an ongoing journey of approvals. Companies are required to monitor for rare adverse events and continual real-world effectiveness, considered the “phase 4” of a clinical trial. They also must maintain their quality control systems, which the FDA will periodically audit.
Selling a biotech product is very different from a consumer good. Though the patient is the one receiving the product, the clinician is often the one deciding whether to use it, and the insurance is the one covering it. This leads to a complex set of negotiations around pricing, coverage, and reimbursements, as well as a marketing challenge to disseminate information about new treatments. While patients ask Dr. Google (or increasingly, ChatGPT), clinicians are also leveraging tools to inform their clinical decisions. The U.S. and New Zealand are unique as the only two countries in the world to allow direct-to-consumer advertising of prescription drugs, as others want to avoid the potential for patient misinformation.
Even manufacturing a product can become quite complicated. One of the reasons Novo Nordisk may have fallen behind Eli Lilly in the diabetics/weight loss market despite being first is that it had substantial difficulties scaling up their manufacturing (though it didn’t help that Eli Lilly’s drug was also more effective). It often involves custom buildouts of bioreactors, spinning up cold supply chains, and negotiations around key input ingredients. And regulation and compliance are even more strict here, ensuring anything that reaches patients maintains quality throughout the process.
Examples: Cellares (cell therapy manufacturing), Ketryx (AI for FDA compliance)
What Next?
This overview still only scratches the surface of biotech. Each paragraph above contains entire industries and enough depth to sustain teams of PhDs and engineers for decades. But if you’ve made it this far and you're still excited, go talk to someone! Communities like Bits in Bio are full of researchers, engineers, and founders eager to collaborate and share ideas. Many biotech companies are hiring, and open to software-first thinkers.
If you want to dive deeper, the next post in this series explores drug discovery in detail. In future posts, I’ll be diving deeper into specific biotech challenges, from clinical trial patterns to biology foundation models. Leave a comment with topics you want to learn more about! And if you're exploring this space too, I'd love to hear what you're building or learning. Reach out anytime.
Thank you to Alex Goldberg, Anton Krutiansky, Ken Leidal, Lina Garcia, Matteus Pan, Ryan Kagin, and Wojtek Swiderski for taking the time to review this post.
Starting In Biotech: Part II

If you’re just learning about biotech and want a broad industry view, consider starting with this overview of the biotech industry and then diving into drug discovery.
Great primer!!
The section on genetic testing hit me — it’s like moving from descriptive analytics (“what’s happening now”) to predictive analytics (“what’s likely to happen”). That’s the same leap we try to make in workforce tech.
Question: Is the space advanced enough to be thinking about putting safeguards in place to make sure predictive diagnostics don’t create harmful feedback loops, the way predictive HR tools sometimes reinforce bias just yet?